Jean-Pierre Bianchi
| LinkedIn
| Skills (endorsed)
| Recommendations
| My Substack
| Email me
| My CV

Jean-Pierre Bianchi
| LinkedIn
| Skills (endorsed)
| Recommendations
| My Substack
| Email me
| My CV
Solutions to various Leetcode problems, with various optimizations in speed, memory, or simply original (see README). Here is my Leetcode profile, showing the types of problems (dynamic programming, divide and conquer etc).
This project shows the full process of building a ML system: defining the problem as a classification task, loading, examining and pre-processing data, establishing a baseline, trying linear models, then non linear ones (kNN, DT,RandomForest, SVM, MLP), then the metrics to select the final model, including the precision-recall curve, pytests at every step, and finally insuring the model isn’t flawed by overfitting on a small sample of the training set on purpose, and feature ablations to check if the model slowly degrades but remains consistent.
This project compares linear algorithms (logistic regression, Perceptron) to non-linear ones (Decision Trees, Random Forest, SVM, multi-layer perceptron) on the MNIST dataset, augmented to handle image rotations. It reaches accuracy of 85% while only using a training dataset of 5000 images due to Colab limitations. It also analyses the influence of noise on training labels, which reveals the good performance of SVM, with no degradation to 10-15% random or non-random noise.
This article explains how to use Numpy meshgrids and broadcasting to vectorize the convolution between a matrix and a kernel like in a CNN, ie parallelize it without a GPU.
Data processing with Pandas, then uni-bi-multivariate analysis. Explanations of skewness and kurtosis
Performance analysis of a website (sales funnel, conversion etc), deployment.
This project shows how to download a podcast from a given RSS link, transcribe it into text, then process it with GPT3.5 to extract various data such as the podcast title, guest name/title/company, highlights and summary.
It demonstrates the steps of a typical ‘GPT/LLM’ application, with different input data.
This project shows how to use Pytorch and Pytorch Lightning to compare the accuracy and methodology of fine-tuning a pre-trained BERT model vs Word2vec for sentiment analysis.
It is typical NLP text classification: ie predict if a sentence has positive or negative sentiment.
This project compares various decoders, encoders with OpenAI basic GPT3.5-turbo and it’s finetuned version for sentiment analysis on financial data.
This project uses parameter efficient fine tuning (PEFT) low rank adaptation (LORA) to fine-tune the microsoft/phi-1.5 and meta-llama/Llama-2-7b-chat-hf models for summarizing scientific papers.
This project conducts detailed model evaluation, data quality testing and behavioral testing for a news classification model.
This project focuses on model performance monitoring for a news classification model.
This project shows how to manage alerts from a simple website deployed in a container with Kubernetes. Basically, several alerts are declare with Prometheus, such as LowMemory, KubePodNotReady and how to send alerts to email and Slack channels. Several strategies to manage Toil are also listed.
A sidebar provides manual settings and metrics to allow users to test various parameters, and get familiar with all the steps involved in, but usually hidden, a typical RAG system. Warning: the free vector db sandbox may have been removed by Weaviate. Also, the finetuning option is not active when the system runs online since it requires Modal credits.
This project retrieves information from financial reports in PDF format, chunks and embeds it using Sentence transformers and stores them in a vector database, which is queried by a LLM. It is accessed from notebooks (no UI), but it may not work since the Weaviate sandbox expires after 2 weeks.
This Agno agent purchases items on a mock ecommerce website according to users’ questions. It can also retrieve a post on Discord through a MCP agent/server configuration. See videos 1 & 2.
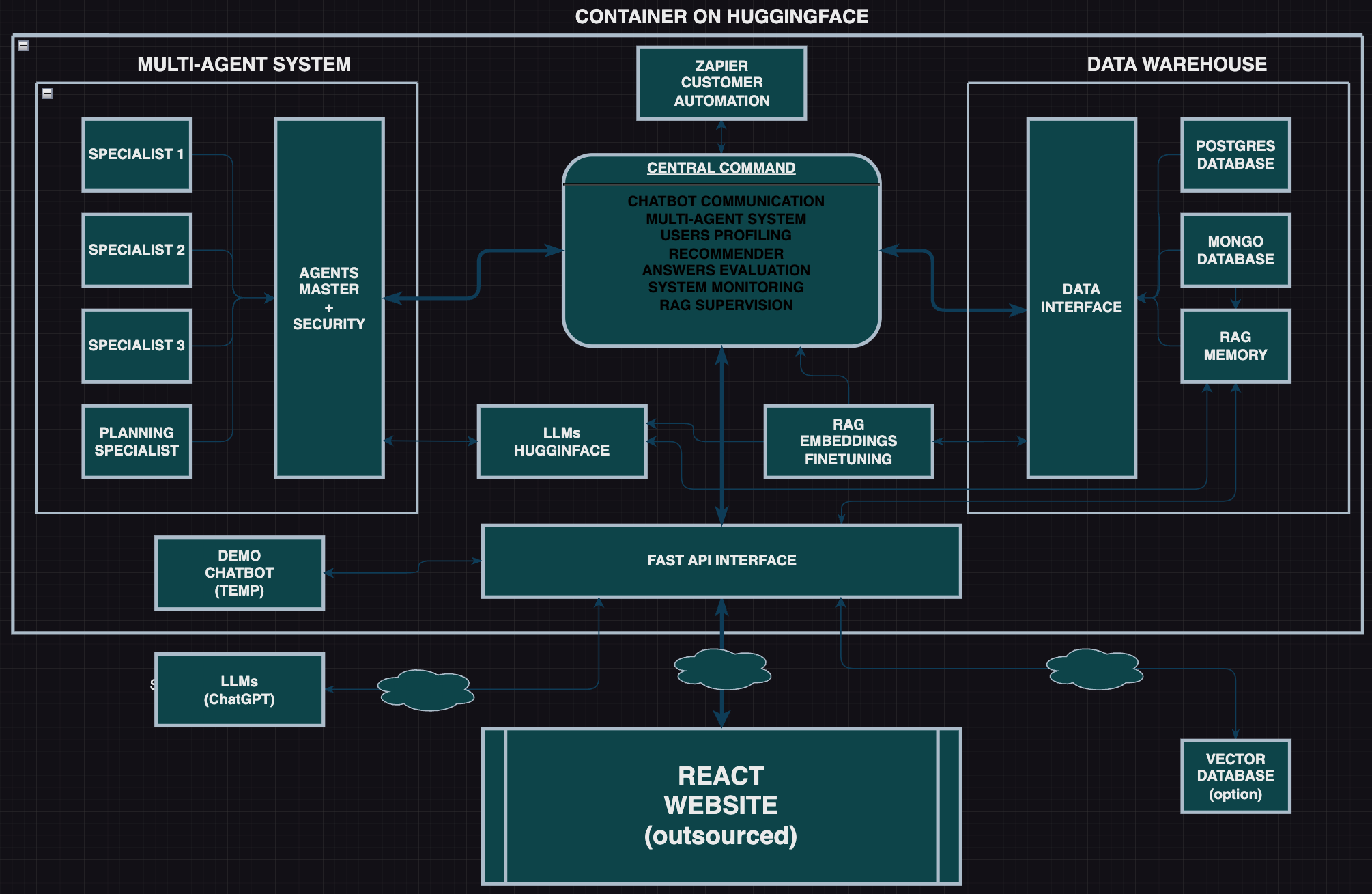
This Agno-based system showcases a flexible architecture that can solve a large range of applications because most AI applications require some form of data input, authentication (security), data engineering, and of course agents to mimic human intelligence for various intellectual tasks, and interfacing with the world through tools. Read the documentation.
